why ontology for text-to-sql?
nicholas chen · november 15, 2025 · 6 min read

what is an ontology?
an ontology is a formal way to represent a set of concepts and categories in a subject area or domain, and the relationships between them. in the context of data engineering and software development, an ontology defines the objects, properties, and relationships that exist within a specific data domain.
think of it as a blueprint that tells the computer exactly what kind of information is available and how different pieces of information connect to each other. it's the bridge between raw, unstructured data and a clear, usable understanding of that data.
without an ontology, a computer sees data as just numbers and strings. with an ontology, it understands that those numbers represent "revenue," and that "revenue" is linked to a "customer" through an "order."
a simple example
imagine a retail company's database. the ontology would define "customer," "product," and "order." it would also specify that a "customer" places an "order," and an "order" contains one or more "products." this simple map allows anyone (or any machine) to ask questions like "which customers bought this specific product?" and get a correct answer based on the underlying data relationships.
why does it matter?
for ai-driven systems like text-to-sql, an ontology is absolutely critical. it provides the necessary context for large language models (llms) to translate natural language questions into accurate sql queries. without a clear ontology, the llm has to guess which tables and columns correspond to the user's request, which often leads to "hallucinations" or incorrect queries.
an ontology helps in several ways:
- • disambiguation: clearly defines what each term means within the domain.
- • context: provides the llm with a map of how data is structured and related.
- • accuracy: significantly reduces the chance of generating incorrect sql by providing a clear schema.
- • efficiency: makes it easier and faster to build and maintain data-driven applications.
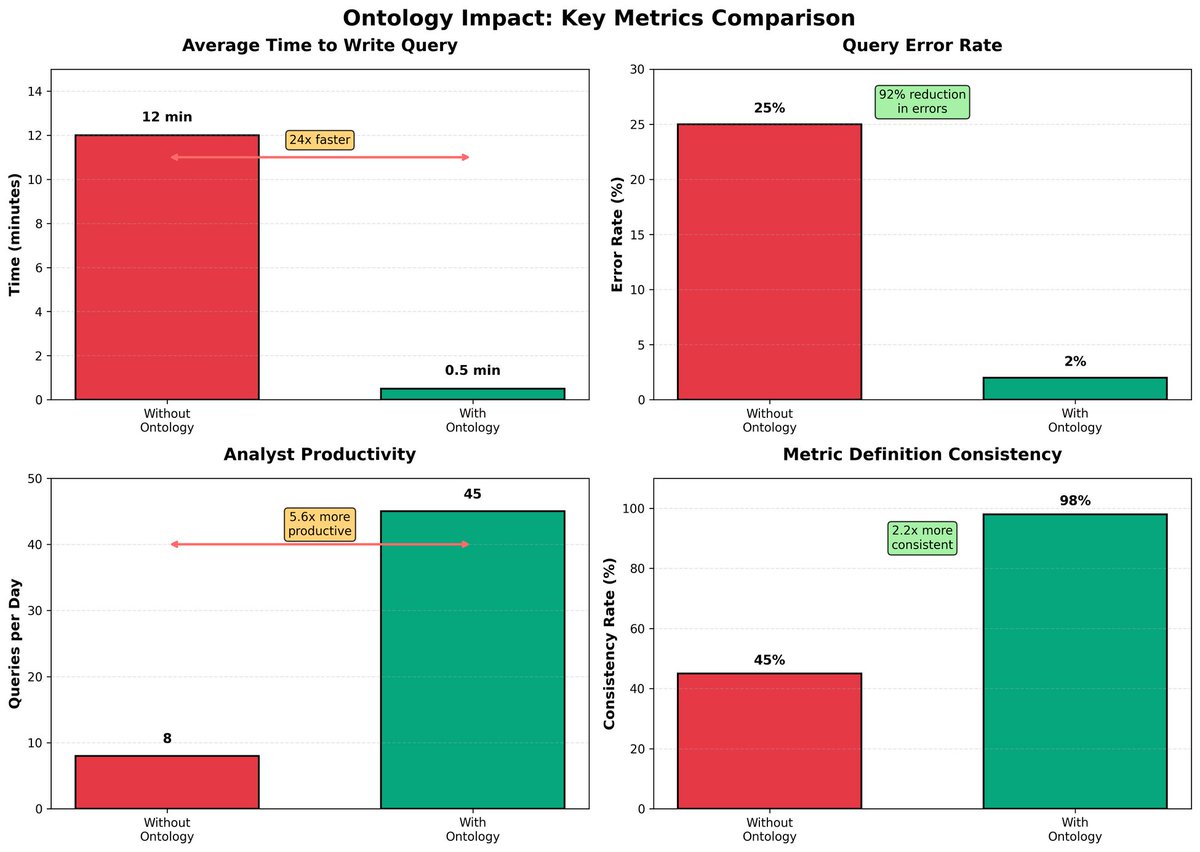
in short, an ontology transforms a database from a pile of tables into a coherent world that an ai can understand and reason about. it moves the complexity of data modeling from the user's head into a formal system that the machine can leverage.
when an llm can see exactly how "gross margin" is calculated and which tables are involved, it can generate the correct query every time, even for highly complex requests. it's the difference between a system that works 60% of the time and one that works 99% of the time.
building the ontology
at textql, we've developed a robust process for building and managing ontologies at scale. it starts with deep domain expertise and a thorough understanding of the underlying data sources. we work closely with data teams to identify the core objects, their attributes, and how they relate to one another.
the process involves several steps:
1. identifying entities: we start by defining the primary "nouns" of the business—customers, orders, subscriptions, products, etc. each entity corresponds to a clear concept that people across the organization understand.
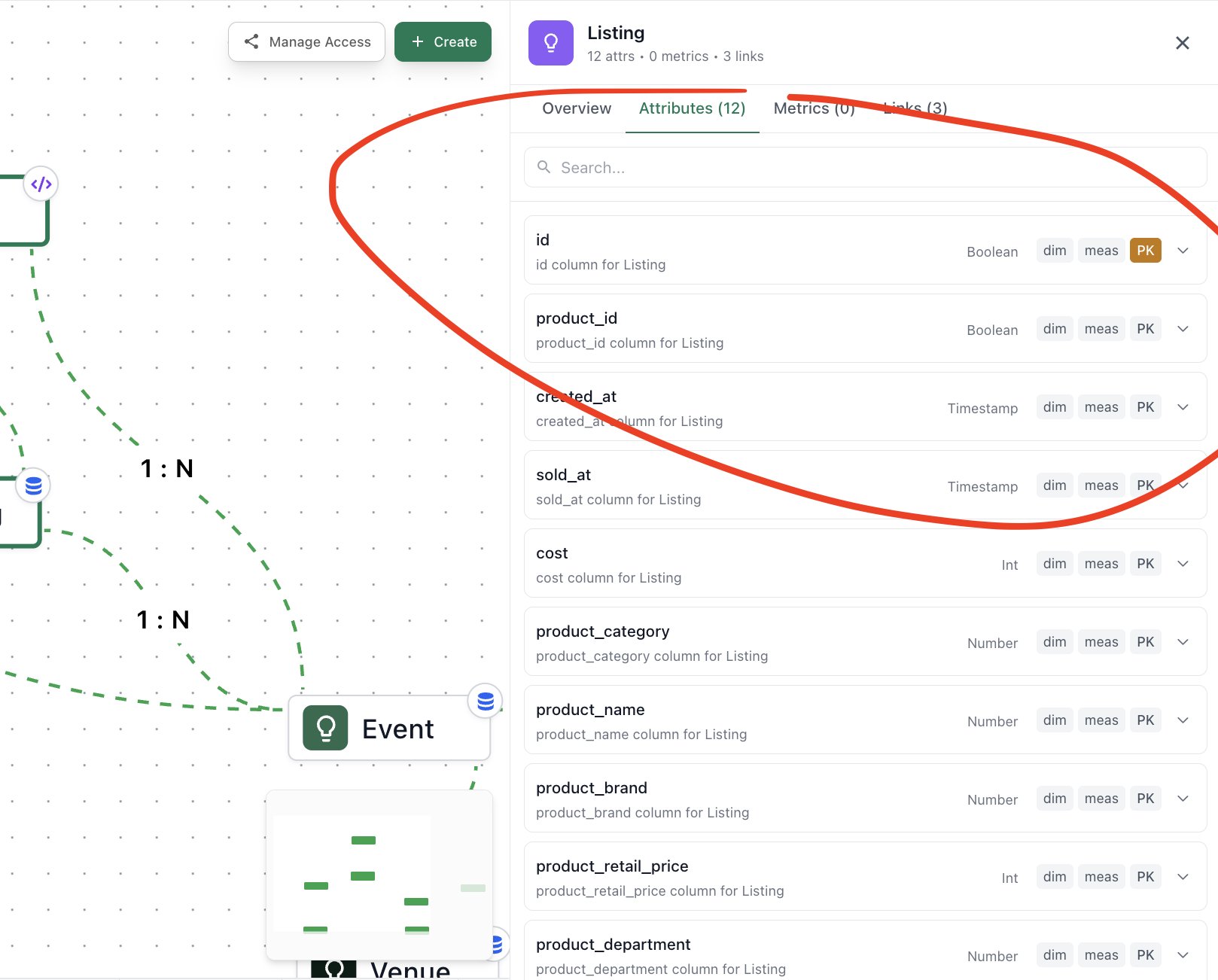
2. defining attributes: for each entity, we identify the relevant fields or columns that describe it. for a customer, this might include their name, email, signup date, and segment.
3. establishing relationships: this is where the map comes together. we define how entities connect. for example, "orders" belong to "customers," and "subscriptions" are linked to both "customers" and "plans."
4. mapping to data sources: once the conceptual model is ready, we map each piece of the ontology to the actual tables and columns in the data warehouse. this creates the bridge between the business logic and the raw data.
5. continuous refinement: an ontology is never truly finished. as the business evolves and new data sources are added, the ontology needs to be updated and refined. we provide tools that make this ongoing maintenance easy and efficient.
is it "good enough"?
building an ontology can feel overwhelming, but it's important to start small. you don't need to model every single column in your database from day one. instead, focus on the 20% of your data that answers 80% of the business questions.
here's what a "good enough" starting point looks like:
- • the 5-10 most important business entities are defined.
- • key relationships between these entities are clearly mapped.
- • core metrics (like revenue or churn) are formally defined within the ontology.
- • the model covers the most common questions people ask about the data.
how engines use it
once an ontology is in place, the text-to-sql engine uses it as its primary source of truth. when a user asks a question, the engine doesn't just look at the raw schema; it looks at the ontology to understand the user's intent within the specific business context.
the engine follows a structured process:
1. intent parsing: the llm analyzes the user's question to identify which ontology objects and attributes are being referenced.
2. schema retrieval: based on the identified objects, the engine pulls the relevant parts of the ontology—including table names, column mappings, and join conditions.
3. context injection: the engine provides the llm with a curated set of context from the ontology, ensuring it has all the information needed to generate an accurate query without being overwhelmed by irrelevant data.
4. query generation: finally, the llm generates the sql query, using the ontology's formal definitions to ensure the syntax and logic are correct.
this approach significantly improves both the reliability and the performance of text-to-sql systems. it allows the engine to handle complex joins, aggregate calculations, and domain-specific logic with ease.
how it is used
beyond text-to-sql, an ontology serves as a central registry for all business logic and data knowledge. it becomes the "single source of truth" for the entire organization, ensuring that everyone is using the same definitions and that data is interpreted consistently across different tools and departments.
representing it in code
we represent our ontologies using a structured format, typically json or yaml, which makes them easy to version control and integrate into automated workflows. this allows teams to manage their data definitions just like they manage their software code.
{
"entities": [
{
"id": "customers",
"table": "public.customers",
"primaryKey": "customer_id",
"attributes": [
{ "id": "customer_id", "column": "customer_id" },
{ "id": "segment", "column": "segment" }
]
},
{
"id": "orders",
"table": "public.orders",
"primaryKey": "order_id",
"attributes": [
{ "id": "order_id", "column": "order_id" },
{ "id": "total_amount", "column": "total_amount" },
{ "id": "status", "column": "status" }
]
}
],
"relationships": [
{
"from": "orders",
"to": "customers",
"type": "many-to-one",
"join": "orders.customer_id = customers.customer_id"
}
],
"metrics": [
{
"id": "revenue",
"label": "revenue",
"expression": "SUM(orders.total_amount)",
"entity": "orders",
"filter": "orders.status = 'completed'"
}
]
}the problem of ambiguity
one of the biggest challenges in data is ambiguity. what does "customer" mean? is it anyone who ever visited the site, or someone who made a purchase? the ontology forces teams to answer these questions once and for all, eliminating confusion and ensuring that data is always used correctly.
by formalizing these definitions in code, we create a system that can automatically resolve these ambiguities during the query generation process, leading to much more reliable and trustworthy results.
vs. other models
dbt (semantic layer): while dbt is great for data transformation, it often lacks the rich, relationship-focused mapping needed for complex ai reasoning. ontologies build upon dbt by adding a more flexible and comprehensive layer of context.
traditional bi models: traditional bi tools like looker or tableau have their own internal models, but these are often locked within the tool itself. an ontology is tool-agnostic, providing a single source of truth that can be used by any application.
database views: views can help simplify a complex schema, but they don't provide the semantic context or relationship mapping that an ontology does. views are a structural solution, whereas ontologies are a semantic one.

the future of ontologies
as the data landscape continues to evolve, we believe that ontologies will become the cornerstone of every modern data stack. the ability to formally represent and share business knowledge is essential for building intelligent, data-driven systems that can truly understand and reason about the world.
we're excited to be at the forefront of this movement, building the tools and technologies that make it possible for every organization to leverage the power of ontologies. the future of data isn't just about collecting more information—it's about understanding what that information actually means.
by creating a shared language for data, we can unlock entirely new levels of productivity and insight, moving beyond simple dashboards to truly intelligent systems that can answer any question, any time.